
Pointer
The Pointer part of the project is nearly done! It’s the hits-per-minute meter. Thanks to the simplicity of the Beat Saber mod, it’s possible to drop an Arudino on the local Wifi, have it listen and respond to a multicast UDP packet, and it’ll automatically get a packet sent to it when a block is hit.
The needle uses an R/C servo motor – simple devices which just need a power supply and a single: a pulse, every 20ms, between 1ms and 2ms long depending on angle (0 through 180 degrees). Here’s a test, fine-tuning the values which go to the edge of the hole in the lid, without destroying the whole thing:
And here’s it hooked up with a “moving average” algorithm, approximating the number of blocks hit per minute.
This didn’t go completely to plan, however. The servo draws so much current when it starts moving (it’s actually a super-powerful, high-torque one – oops), the Arudino power supply can’t cope, the voltage drops, and the whole thing resets. So for now, there are some AA batteries in there, just for the servo.
The servo is also a bit imprecise. It tends to jerk around a bit, even on its own. If I have time to revisit, I’ll put a more precision, lower-torque servo in there.
All that’s help is the paint job…

It’ll be a matte black base and backplate, gloss white “grid”, and metallic gold pointer (of course, it just looks brown in this photo…).
Bright Lights
I did some experimentation to find an appropriate resistor value for the LEDs I’m using.

The individual MOSFETs and resistors have now arrived, so getting the first cube hooked up is up next!
AI Datasets
Finally, I’ve progressed the BeatBrain API. The amount of sessions recorded has been steadily growing, and of course at some point it’s necessary to extract the data to train the AI.
Typically you want a decent spread of samples for each of the possible classifications of data: 1,000 for each is recommended as a basis. In this case, I’m looking to guess the user for a given sample, so that’s 1,000 samples per user. To get a good representation of each person, I created an algorithm to select the most diverse set of samples for that person, i.e. a range of different difficulties, settings, speeds and tracks are better.
This is because if possible I don’t want it to recognise a person for the wrong reasons. Say they play one track a great deal which features some fancy movement, and no-one else plays that track. The AI could basically associate that fancy movement with that person – not strictly incorrect, but I want the detection to be based on something more fundamental in the data. If the samples instead have a wide spread for everyone, I believe this effect should be minimised.
The other fun part of this work was collating the dataset file. It’s basically served up as a ZIP file download with tens of thousands of CSVs. The joy of .NET Core, async and working with streams means that the ~1.2GB file is produced without any real load on the server: the API process sits at ~5% CPU, ~75MB(!!) RAM throughout the process as the data is transparently downloaded and parsed from Google Cloud.
Here’s a graph of one sample – this is an example of what the AI will have to look at, to try to determine the person behind it:
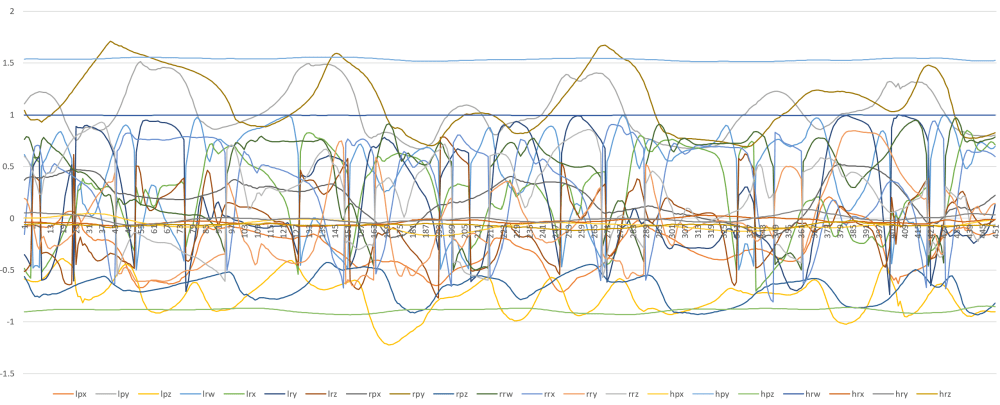
Already I’ve made a good few guesses – the number of samples per user (1,000), how they’re split (600 training / 200 test / 200 validation), the length of samples (5 sec), the format of the values (currently raw position / quarternions .. though the latter means some values ‘wrap around’ when rotating).
I’ll be getting stuck in with RNNs and Keras soon, so tweaking all of these as “hyperparameters” (see here, if I’m using the term correctly) is sure to be fun.
Something to think about – different VR headsets have different capture frameworks, it seems. Vive looks to be about double that of the Rift…
